All Platforms
Company Updates
News, product launches, awards, and insights from instarea — all in one place.
213 posts
2026
24 posts
From Mobile Network Data to Foot Traffic: The 7-Step RGL Flow
How RGL turns mobile network data into real-time foot traffic — a 7-step flow from geofence setup to coupon redemption, powered by 8 years of telecom infrastructure.
From Mobile Network Data to Foot Traffic — We're Piloting the Concept
We're piloting a concept that turns mobile network data into real-time foot traffic. 7 steps, one API, no app required. Here's how RGL works — from geofence setup to coupon redemption.

Do More With Less: How 1 Engineer + AI Agents Replaced a 5-Person Team
HomeGrif runs on 1 senior engineer + AI agents — delivering the output of a 5-person team. Not in theory. In production for 12+ months. Here's the architecture.
Do More With Less: How 1 Engineer + AI Agents = 5-Person Team
HomeGrif runs on 1 senior engineer + AI agents — delivering the output of a 5-person team. Not in theory. In production for 12+ months. Here's the architecture.
HomeGrif: How We Build a Product Nobody's Seen Before
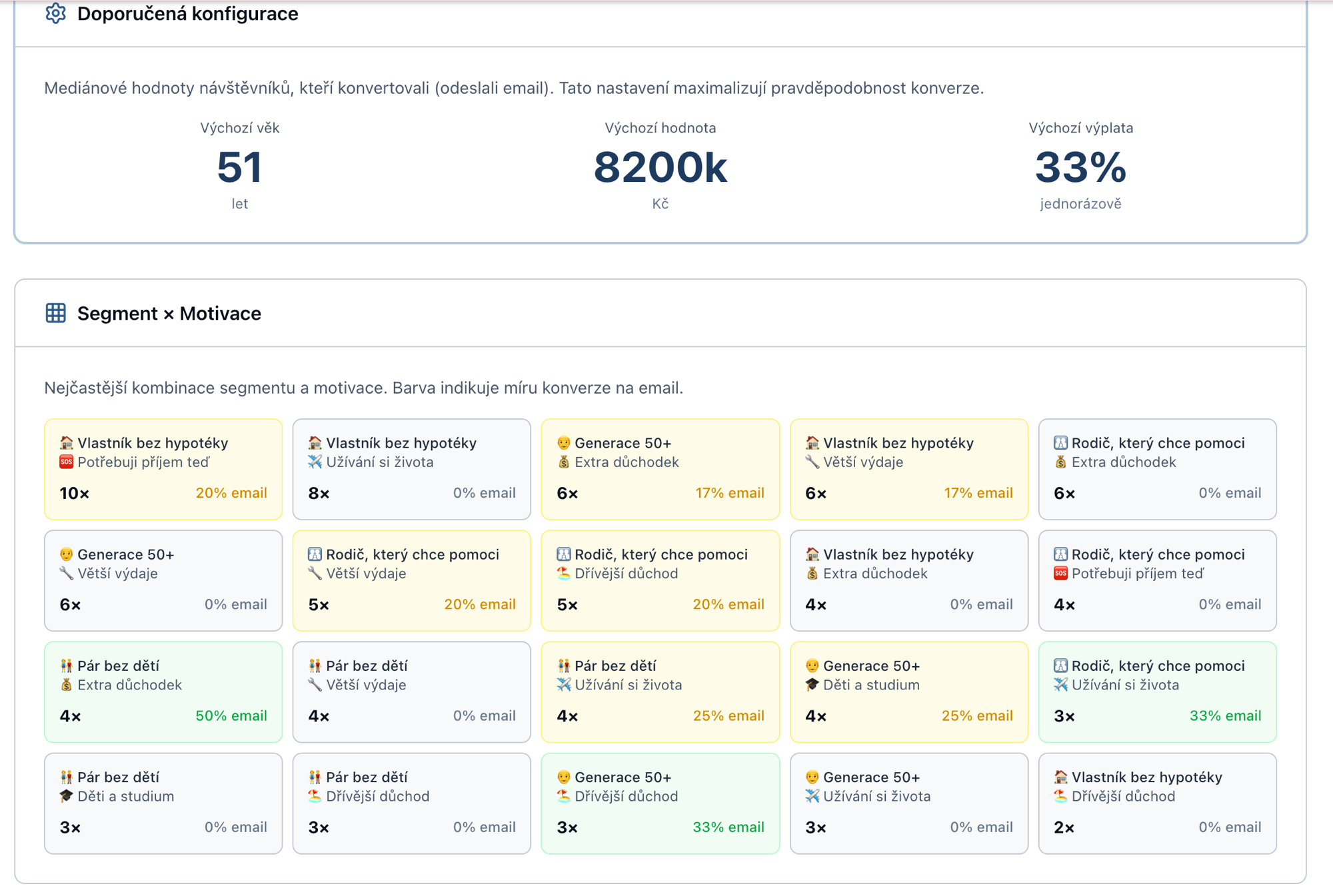
Session randomization, institutional co-design, and user co-creation — the three pillars behind building equity release for a market that doesn't exist yet.
We Don't Do Market Research. We Let the Market Research Itself.
How HomeGrif uses session randomization instead of traditional surveys to discover what users actually want — by watching behavior, not asking questions.
HomeGrif: Building a Product Nobody's Seen Before
HomeGrif uses session randomization, institutional co-design, and user co-creation to build equity release for Central Europe — a €64B market with zero local players.

Oncoteam: AI Tool for Cancer Patient Advocates
instarea's CEO built an open-source AI tool for cancer patient advocates — monitors 500+ clinical trials, analyzes lab trends, works through WhatsApp and Claude.ai. All data stays in the patient's Google Drive.
Oncoteam: Open-Source AI for Cancer Patient Advocates
Peter built Oncoteam — an open-source AI tool for cancer patient advocates. 19 agents, 500+ clinical trials, lab analysis, WhatsApp + Claude.ai integration. Free during active treatment.
Oncoteam: Open-Source AI for Cancer Patient Advocates
Peter built two open-source tools for cancer patient caregivers — Oncofiles organizes medical documents, Oncoteam analyzes lab trends and matches clinical trials. Free during active treatment.

Geo API: New Revenue Stream on Proven Telco Infrastructure
After 8 years running geolocation consent platforms at Slovak Telekom and Orange, instarea is launching Geo API — enabling enterprises and government to use operator location infrastructure via a single integration.
From Hobby to Production — When Your Side Project Needs Real Engineering
Your vibecoded MVP works for 100 users. But what happens at 100,000? Here's when and why you need to elevate from hobby to production-grade engineering.

Geodata Monetization for MNOs — Two Models, One Platform
How mobile network operators can turn geolocation consents into revenue through first-party and third-party data monetization models — with a single GDPR-compliant platform.

Geodata Monetization for MNOs — Two Models, One Platform
Mobile operators sit on one of the most valuable data assets in the world. Two clear monetization paths: consent-based geolocation and GeoAPI for trusted parties.
Geodata monetization for mobile operators — why it matters in Slovakia too
Geodata monetization for mobile operators — why it matters in Slovakia too At instarea® is.

Engineers Are Still Needed — Enterprise Engineering in the Vibecoding Era
In an era of AI-generated code and no-code tools, why do companies still need real engineers? Because architecture, security, DevOps, and production robustness can't be vibecoded.
Engineers Are Still Needed — Enterprise Engineering in the Vibecoding Era
Peter Fusek argues that enterprise engineering expertise remains indispensable even in the vibecoding era — because architecture that scales, security that holds, reliable DevOps, and cost optimization are disciplines that AI-generated code cannot yet replace. instarea's longest partnership, Market Locator with Slovak Telekom running for over a decade, illustrates why production-grade architecture decisions compound in value over time.

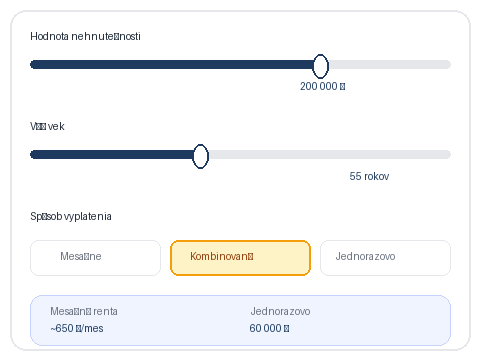
Equity Release Doesn't Exist in Central Europe. Yet.
We're in talks with financial institutions in Czech Republic and Slovakia to pilot a lifetime home equity product for the 50+ generation. In Slovakia 91% of seniors own their home but the average pension is just €620/month.
In Slovakia, 91% of seniors own their home. Average pension: €620/month.
In Slovakia, 91% of seniors own their home. Average pension: €620/month. In Czechia: a flat worth €160-200K, pension €840/month.

In Slovakia, 91% of Seniors Own Their Home
Average pension €620/month. Property worth €160-200K. Sitting on a goldmine, eating bread rolls. We're researching how to unlock this wealth for Slovakia's seniors.

The Concrete Wealth Trap: Why Are CEE Seniors Paper-Rich but Cash-Poor?
Slovak households 65+ have median €3,750 in cash. But €97,000 locked in real estate. 91.7% of their wealth frozen in property they can't spend.
Employee Pulsechecks and AI Replicas for Market Research
AI-powered surveys and employee pulsechecks via AI Living Replicas. Linked to the 2muse podcast 'VYTVÁRAME AVATAROV!' — a YouTube discussion on Replica.city and digital twin market research.
The Concrete Wealth Trap: Why are CEE seniors paper-rich but cash-poor?
The Concrete Wealth Trap: Why are CEE seniors paper-rich but cash-poor? Slovak households 65+ have median €3,750 in cash.
The Concrete Wealth Trap: Why are Central European seniors asset-rich but…
📊 The Concrete Wealth Trap: Why are Central European seniors asset-rich but cash-poor?